Featured
Running LLaMA Locally with Llama.cpp: A Complete Guide
Llama.cpp is a powerful and efficient inference framework for running LLaMA models locally on your machine. Unlike other tools such as Ollama, LM Studio, and similar LLM-serving solutions, Llama.cpp is designed to provide high-performance, low-resource inference while offering flexibility for different hardware architectures.

Introduction
Have you ever wanted to run large language models (LLMs) on your own machine without relying on cloud services? Llama.cpp makes this possible! This lightweight yet powerful framework enables high-performance local inference for LLaMA models, giving you full control over execution, performance, and optimization.
In this guide, we’ll walk you through installing Llama.cpp, setting up models, running inference, and interacting with it via Python and HTTP APIs. Whether you’re an AI researcher, developer, or hobbyist, this tutorial will help you get started with local LLMs effortlessly.
Why Choose Llama.cpp?
Before diving into installation, let’s compare Llama.cpp to other solutions:
- Llama.cpp vs. Ollama: While Ollama provides built-in model management with a user-friendly experience, Llama.cpp gives you full control over model execution and hardware acceleration.
- Llama.cpp vs. LM Studio: LM Studio features a GUI, whereas Llama.cpp is designed for CLI and scripting automation, making it ideal for advanced users.
Key Advantages of Llama.cpp:
- Optimized for CPU inference while supporting GPU acceleration.
- Works across Windows, Linux, and macOS.
- Allows fine-tuned control over execution, including server mode and Python integration.
Now, let’s get started with setting up Llama.cpp on your system.

Installation Guide
For detailed build instructions, refer to the official guide: [Llama.cpp Build Instructions]. In the following section I will explain the different pre-built binaries that you can download from the llama.cpp github repository and how to install them on your machine
Windows Setup
Choosing the Right Binary
If you’re downloading pre-built binaries from Llama.cpp’s releases page [Link], choose based on your CPU and GPU capabilities:
- AVX (
llama-bin-win-avx-x64.zip): For older CPUs with AVX support. - AVX2 (
llama-bin-win-avx2-x64.zip): For Intel Haswell (2013) and later. - AVX-512 (
llama-bin-win-avx512-x64.zip): For Intel Skylake-X and newer. - CUDA (
llama-bin-win-cuda-cu11.7-x64.zip): If using an NVIDIA GPU.
If unsure, start with AVX2 as most modern CPUs support it. For GPUs, ensure your CUDA driver version matches the binary.
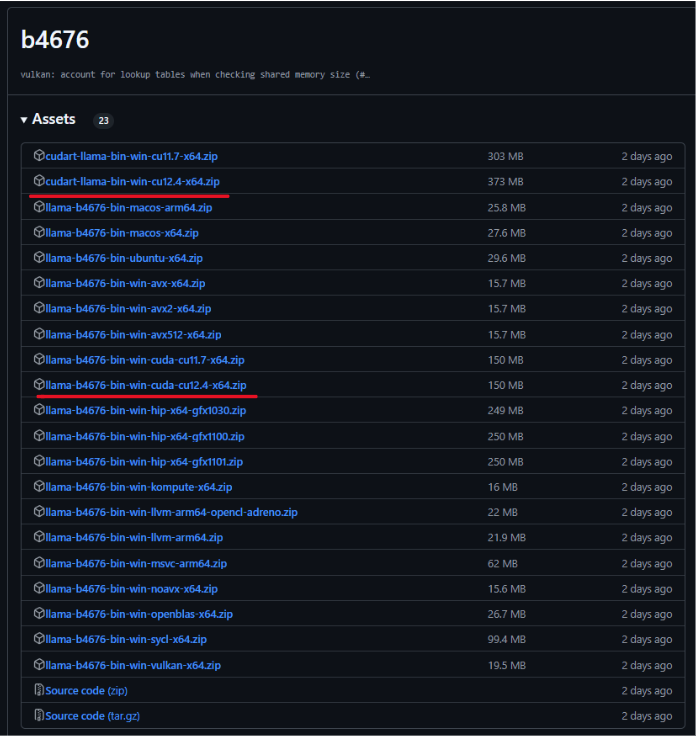
For this tutorial I have CUDA 12.4 installed in my PC so I downloaded the llama-b4676-bin-win-cuda-cu12.4-x64.zip and cudart-llama-bin-win-cu12.4-x64.zip and unzip them and placed the binaries in a directory and added this directory to my path environment variables.
Linux & macOS Setup
For Linux and macOS, download the appropriate binaries:
- Linux:
llama-bin-ubuntu-x64.zip - macOS (Intel):
llama-bin-macos-x64.zip - macOS (Apple Silicon M1/M2):
llama-bin-macos-arm64.zip
After downloading, extract the files and add the directory to your system’s PATH to execute commands globally.
you can also use the following installation using curl in linux
curl -fsSL https://ollama.com/install.sh | shAfter Downloading the right files, unzipping and adding the extracted directory to your system’s environment variables to run the executables from any location, now we are ready to explore the functionalities of llama.cpp.
Understanding GGUF, GGML, Hugging Face, and LoRA Formats
What is GGUF?
GGUF (Generalized GGML Unified Format) is an optimized file format designed for running large language models efficiently using Llama.cpp and other frameworks. It improves compatibility and performance by standardizing how model weights and metadata are stored, allowing for efficient inference on different hardware architectures.
What is GGML?
GGML (Generalized Gradient Model Language) is an earlier format used for LLM inference that supports quantized models, making them more memory-efficient. However, GGUF has largely replaced GGML due to its enhanced features and improved performance.
Converting GGML to GGUF
If you have a GGML model and need to use it with Llama.cpp, you can convert it to GGUF using a conversion script.
Example command:
python convert_llama_ggml_to_gguf.py - input model.ggml - output model.ggufThe convert_llama_ggml_to_gguf.py script exists in the llama.cpp github repository in the main directory.
Hugging Face Format
Hugging Face models are typically stored in PyTorch (.bin or .safetensors) format. These models can be converted into GGUF format using conversion scripts like convert_hf_to_gguf.py.
LoRA Format
LoRA (Low-Rank Adaptation) is a fine-tuning technique used to efficiently adapt large language models to specific tasks. LoRA adapters store only the fine-tuned weight differences rather than modifying the entire model. To use LoRA with Llama.cpp, you may need to merge LoRA weights with a base model before conversion to GGUF using convert_lora_to_gguf.py.
Downloading GGUF Model Files from Hugging Face
You can download GGUF model files from Hugging Face and use them with Llama.cpp. Follow these steps:
- Visit Hugging Face Models Page: Go to Hugging Face and search for LLaMA or any model compatible with GGUF. in this tutorial we will use the mistral gguf files downloaded from this link
- Download the Model: Navigate to the model’s repository and download the GGUF version of the model. If the GGUF format is not available, you may need to convert it manually as explained before.
- Move the File: Place the downloaded or converted GGUF model into your
models/directory.
Run a model
Now we can use the command llama-cli that is one of the executables that we have downloaded, you can check all the flags that can be used with the llama-cli command to trigger the llm model using the gguf file.
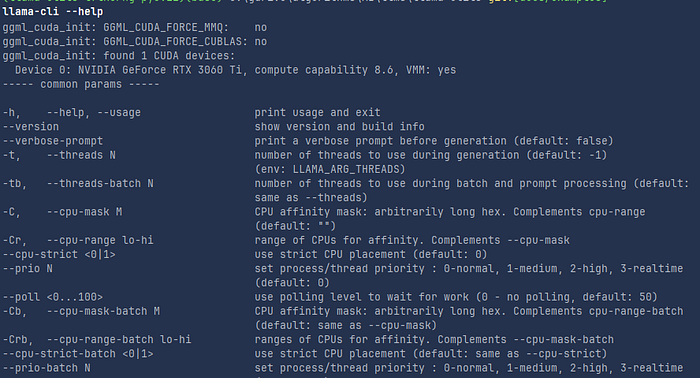
at the end of the help list of the llama-cli utility, there are two examples of triggering a text generation, and a chat.
Interacting with Llama.cpp in Python
Overview of llama-cpp-python
The llama-cpp-python package provides Python bindings for Llama.cpp, allowing users to:
- Load and run LLaMA models within Python applications.
- Perform text generation tasks using GGUF models.
- Customize inference parameters like temperature, top-k, and top-p for more controlled responses.
- Run models efficiently on both CPU and GPU (if CUDA is enabled).
- Host models as an API server for easy integration into applications.
Installing Required Packages
You can use llama-cpp-python, which provides Python bindings for llama.cpp:
pip install llama-cpp-pythonRunning Inference in Python
Now we can use the llm model gguf file that we have downloaded above, load it in python using the llama_cpp package and trigger the chat completion function
from llama_cpp import Llama
llm = Llama(model_path="mistral-7b-instruct-v0.2.Q2_K.gguf")
response = llm.create_chat_completion(
messages=[
{
"role": "user",
"content": "how big is the sky"
}
])
print(response)The response will be something like
```plaintext
{
'id': 'chatcmpl-e8879677-7335-464a-803b-30a15d68c015',
'object': 'chat.completion',
'created': 1739218403,
'model': 'mistral-7b-instruct-v0.2.Q2_K.gguf',
'choices': [
{
'index': 0,
'message':
{
'role': 'assistant',
'content': ' The size of the sky is not something that can be measured in a way that
is meaningful to us, as it is not a physical object with defined dimensions.
The sky is the expanse above the Earth, and it includes the atmosphere and the outer
space beyond. It goes on forever in all directions, as far as our current understanding
of the universe extends. So, we cannot assign a specific size to the sky.
Instead, we can describe the size of specific parts of the universe, such as the diameter
of a star or the distance between two galaxies.'
},
'logprobs': None,
'finish_reason': 'stop'
}
],
'usage': {
'prompt_tokens': 13,
'completion_tokens': 112,
'total_tokens': 125
}
}
```Downloading and Using GGUF Models with Llama.from_pretrained
The Llama.from_pretrained method allows users to directly download GGUF models from Hugging Face and use them without manually downloading the files.
Example:
from llama_cpp import Llama
# Download and load a GGUF model directly from Hugging Face
llm = Llama.from_pretrained(
repo_id="TheBloke/Mistral-7B-Instruct-v0.2-GGUF",
filename="mistral-7b-instruct-v0.2.Q4_K_M.gguf"
)
response = llm.create_chat_completion(
messages=[
{"role": "user", "content": "How does a black hole work?"}
]
)
print(response)This method simplifies the process by automatically downloading and loading the required model into memory, eliminating the need to manually place GGUF files in a directory. and loading the gguf file from that directory.
'id': 'chatcmpl-e8879677-7335-464a-803b-30a15d68c015',
'object': 'chat.completion',
'created': 1739218403,
'model': 'mistral-7b-instruct-v0.2.Q2_K.gguf',
'choices': [
{
'index': 0,
'message':
{
'role': 'assistant',
'content': ' The size of the sky is not something that can be measured in a way that
is meaningful to us, as it is not a physical object with defined dimensions.
The sky is the expanse above the Earth, and it includes the atmosphere and the outer
space beyond. It goes on forever in all directions, as far as our current understanding
of the universe extends. So, we cannot assign a specific size to the sky.
Instead, we can describe the size of specific parts of the universe, such as the diameter
of a star or the distance between two galaxies.'
},
'logprobs': None,
'finish_reason': 'stop'
}
],
'usage': {
'prompt_tokens': 13,
'completion_tokens': 112,
'total_tokens': 125
}
}- you can use the
cache_dirparameter to specify the directory where the model will be downloaded and cached.
Running Llama.cpp as a Server
You can run llama.cpp as a server and interact with it via API calls.
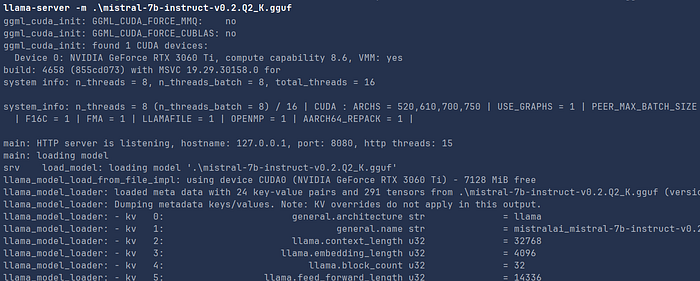
Start the Server
llama-server -m mistral-7b-instruct-v0.2.Q2_K.gguflaunching the model as a server in your terminal will give the following response.
Send Requests Using Python
import requests
# Define the API endpoint
url = "http://localhost:8000/completion"
# Define the payload
payload = {
"model": "mistral-7b-instruct-v0.2.Q4_K_M.gguf",
"prompt": "How big is the sky?",
"temperature": 0.7,
"max_tokens": 50
}
headers = {"Content-Type": "application/json"}
try:
response = requests.post(url, json=payload, headers=headers)
# Check if the request was successful
if response.status_code == 200:
# Parse the response JSON
response_data = response.json()
# Extract the result from the response
choices = response_data.get("choices", [])
if choices:
result = choices[0].get("text", "")
print("Response:", result)
else:
print("No choices found in the response.")
else:
print(f"Request failed with status code {response.status_code}: {response.text}")
except Exception as e:
print(f"Error occurred: {e}")The response will be something like
Response:
The sky is not a tangible object and does not have physical dimensions, so it cannot be measured or quantified in the same way that we measure and quantify objects with size or dimensions. The sky is simply the vast expanse ofSend Requests from Terminal (Linux/macOS) or PowerShell (Windows)
curl -X POST "http://localhost:8000/completion" \
-H "Content-Type: application/json" \
-d '{"prompt": "Tell me a fun fact.", "max_tokens": 50}'Conclusion
This tutorial covered installing, running, and interacting with Llama.cpp on different platforms. You can now integrate Llama models into your applications for local inference and API-based interactions.

